[C02 머신러닝 프로젝트 AtoZ]06 데이터 시각화
데이터 탐색 시 주의할 점
- 훈련 세트만 가지고 탐색을 한다. 절대 테스트 세트를 보지 않는다
- 훈련 세트의 크기가 너무 커서 시각화하는데 시간이 소요된다면, 탐색과 시각화를 위한 세트를 별도로 샘플링해도 된다
- 여기서는 크기가 작으므로 훈련 세트 전체를 사용해도 좋다
- 훈련 세트를 손상시키지 않기 위해 복사본을 만들어서 쓰는 것이 좋다
import pandas as pd
# 첫 번째 컬럼이 우리가 만든 index이므로 index_col=0을 지정해준다.
strat_train_set = pd.read_csv("../datasets/temp/strat_train_set.csv", index_col=0)
훈련 세트 복사본 만들기
- 여기서는 ipynb 파일이 분리되어 있어 파일을 불러와 사용하니 문제없지만, 실제로는 훈련 세트를 복사본을 만들어서 사용하는 것이 좋다
housing = strat_train_set.copy()
지리 정보(위도 경도)가 있으니, 산점도를 그려보자.
housing.plot(kind="scatter", x="longitude", y="latitude")
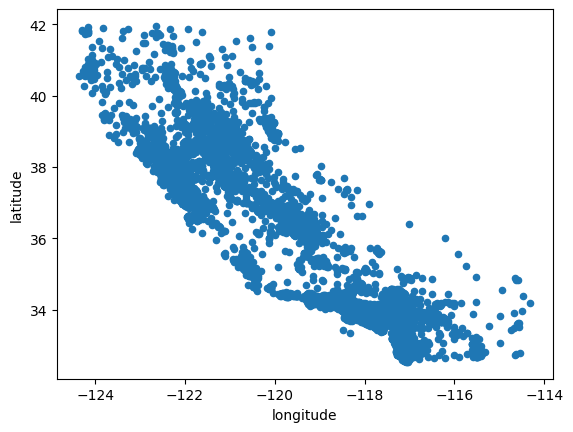
데이터 밀집 확인하기
- alpha 옵션을 0.1로 주면 기본적으로 점이 매우 연하게 찍히고, 밀집된 지역은 점들이 여러 번 찍혀 진해지기 때문에 밀집도를 확인하기 아주 좋다
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
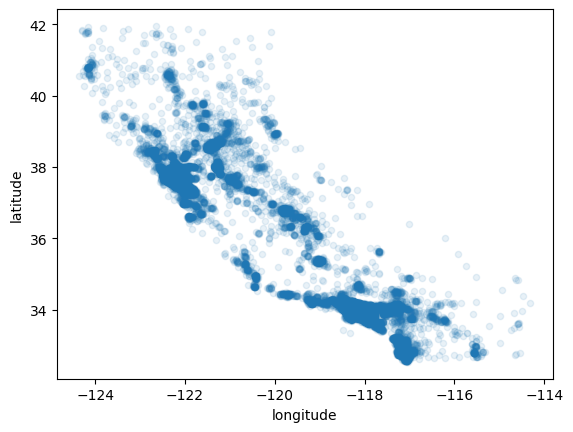
특성을 색으로 확인하자
- 원의 반지름(s)으로 구역의 인구를 나타내보자
- 색상(c)으로 가격을 나타내보자 -jet라는 컬러맵을 사용할 것임
import matplotlib.pyplot as plt
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
figsize=(10,7))
plt.legend()
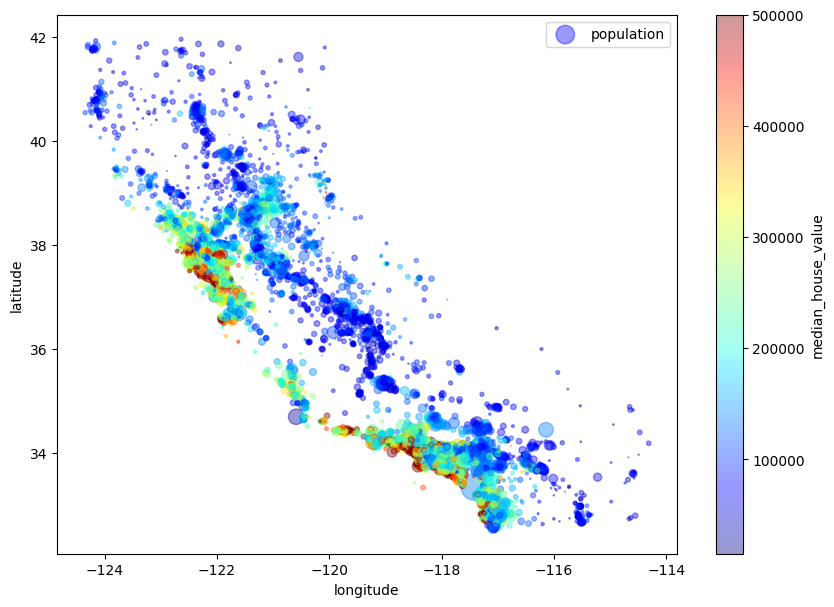
산점도에서 얻은 시사점
- 해안 근접성이 가격에 영향을 미친다
- 밀집된 지역이 가격이 높다
- 일단 서부 해안과 인접한 곳이 비싸 보인다.
- 북부 지역은 또 그렇지 않아서 해안 접근성이라는 특성을 단순하게 일괄 적용하기는 간단하지 않다
- 인구 밀도에 영향을 받는다
- 군집 알고리즘으로 주요 근집을 찾고, 근집의 중심까지의 거리를 재는 특성을 추가할 수도 있다.
상관계수 구하기
- 데이터셋의 모든 특성들의 표준 상관계수를 구하고, 정렬해서 내림차순으로 나열해보자
#corr_matrix = housing.corr()
corr_matrix = housing.corr(numeric_only=True)
corr_matrix["median_house_value"].sort_values(ascending=False)
산점도를 그려 특성간의 상관관계를 더 자세히 알아보기
- pandas의 scatter_matrix 함수를 쓰면 각 숫자형 특성들 사이에 산점도를 그려준다.
- 그냥 그리라고 하면 11개 특성 전부에 대해 11 X 11 플롯이 그려진다.
- 특성 몇 개만 지정해서 그려보자
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing[attributes], figsize=(8, 5))
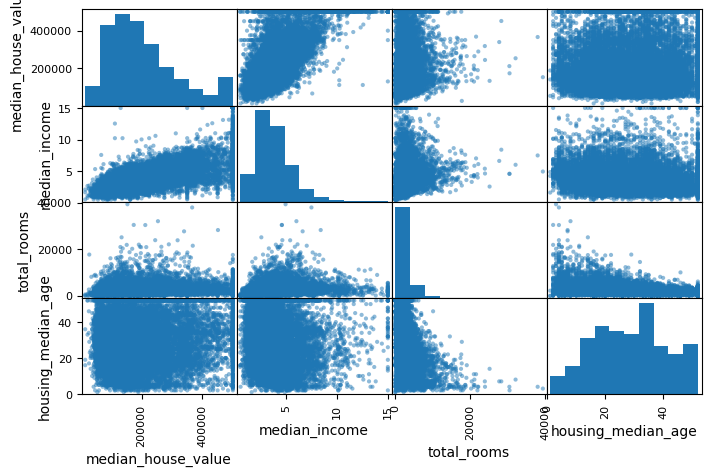
- 대각선(왼쪽위 - 오른아래)은 변수 자신에 대한 것이라 걍 직선이므로 쓸모가 없음
- 그래서 판다스는 디폴트로 여기에 각 특성의 히스토그램을 그리게 되어 있음
- 이 옵션을 변경하고 싶다면 커널 밀도 추정(diagonal = kde) 옵션을 주면 됨
# median_income과 median_house_value 사이의 상관관계가 매우 강하니, 두 특성의 산점도를 확대해서 그려보자.
housing.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1)
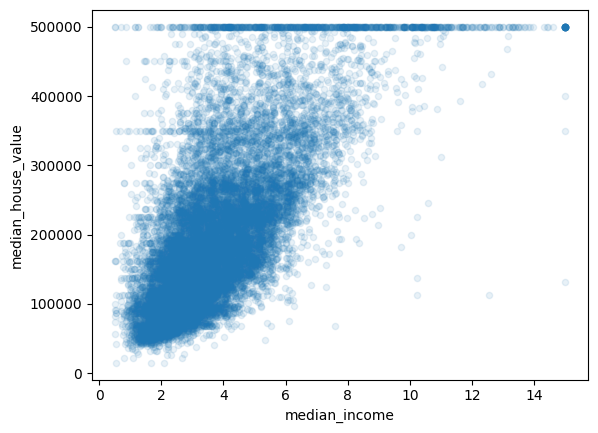
상관관계 그래프 해석
- 상관관계가 매우 강하게 우상향
- 가격 제한값이 50만$에서 수평선으로 잘 보임
- 45만, 35만, 28만 정도에서 수평선들이 보임 > 이런 이상한 형태를 학습하는 것은 안 좋기 때문에, 제거하자
특성공학
- 머신러닝 알고리즘용 데이터를 실제로 준비하기 전에 마지막으로 해야 할 것은 특성들을 조합해서 새로운 특성을 만들어내는 것이다.
- 예를 들어 특정 구역에 방이 몇 개인지(전체 방 개수)보다는 가구당 방 개수가 집값을 예측하는데 더 중요하다.
# rooms_per_household, bedrooms_per_room, population_per_household 특성을 추가해보자.
housing["rooms_per_household"] = housing["total_rooms"] / housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"] / housing["total_rooms"]
housing["population_per_household"] = housing["population"] / housing["households"]
# 상관관계 행렬을 다시 확인해보자.
# 원래는 corr() 함수를 호출하면 알아서 numeric 특성끼리만 계산했었는데, 앞으로의 업데이트에서는 default 값이 false로 바뀔 것이라고 경고가 뜬다.
# 경고를 없애기 위해, 그리고 앞으로 업데이트 될 것을 대비해 numeric_only=True를 해줘야 한다.
corr_matrix = housing.corr(numeric_only=True)
corr_matrix["median_house_value"].sort_values(ascending=False)
Leave a comment